Introduction
Over the past five months, our team undertook a challenge: to develop and release an internal testing product without any human-written code.
Currently, the product has internal daily active users and external Alpha testers. It runs, deploys, errors, and accepts fixes in a real development environment. What makes it unique is that every line of code, from application logic to test scripts, CI configuration, documentation, observability, and internal tools, was generated by Codex. We estimate that this development model is highly efficient, taking only 10% of the time required for manual code development.
Human at the Helm, Agent in Action
We intentionally set this limitation to see if engineering efficiency could achieve a breakthrough. At that time, we needed to deliver over a million lines of code in just a few weeks, which forced us to rethink: if engineers no longer consider “writing code” their primary job, but instead focus on designing environments, defining intents, and building feedback loops for Codex Agent to produce reliable results, how would the development model change?
In this article, we will share insights from building a new product through the Agent team, including which attempts failed, which yielded compounding effects, and how to maximize our most valuable resources: human time and attention.
Starting from an Empty Repository
At the end of August 2025, we submitted our first commit to this empty repository.
The initial scaffolding was generated by Codex CLI calling GPT-5, supplemented by a few existing templates as guidance, covering repository structure, CI configuration, formatting rules, package manager settings, and application framework. Even the initial AGENTS.md file, which guides the Agent on how to work within the repository, was authored by Codex.
There was no pre-existing human-written code to serve as an “anchor” for the system. From the outset, the entire shape of the repository was molded by the Agent.
Five months later, the repository has approximately one million lines of code, covering application logic, infrastructure, toolchains, documentation, and internal development components. During this time, a small team of just three engineers drove Codex to open and merge around 1500 PRs, averaging 3.5 PRs per engineer per day. Surprisingly, as the team expanded to seven members, the per capita output rate further increased.
More importantly, this was not output for the sake of quantity: the product has been used by hundreds of internal users, including core users who use it heavily every day. Throughout the entire development process, humans never directly contributed a single line of code. This became the core philosophy of the team: refusing to write code manually.
Redefining the Engineer’s Role
With engineers no longer writing code themselves, their focus shifted to system design, scaffolding, and leveraging efficiency.
Early progress was slower than expected, not due to Codex’s limitations, but because the environment lacked sufficient “normativity.” The Agent lacked the tools, abstractions, and internal structures needed to achieve high-level goals. Thus, the engineering team’s primary task became empowering the Agent to work effectively.
In practice, this meant adopting a depth-first approach: breaking down grand objectives into small building blocks (design, code, review, testing, etc.). Driving the Agent to construct these blocks and using existing blocks to unlock more complex tasks. When tasks failed, the fix was almost never to “try again.” Since work had to advance through Codex, human engineers would intervene and think: “What capability is missing? How can we make this capability clear and enforceable for the Agent?”
Human interaction with the system was almost entirely completed through prompts: engineers describe a task, run the Agent, and authorize it to open a Pull Request. To advance the PR to final merge, we instruct Codex to review its code changes locally and request cross-reviews from other specific Agents (whether locally or in the cloud). Codex responds to feedback from humans or Agents and iterates in a loop until all Agent reviewers are satisfied—this effectively forms a so-called “Ralph Wiggum Loop.” Codex directly calls our standard development tools (such as GitHub CLI gh, local scripts, and skills integrated into the repository), autonomously fetching context without human manual copy-pasting in the command line.
Increasing Application Readability
As the code output rate increased, our bottleneck became human QA capacity. Since human time and attention are the only scarce resources, we aimed to enhance the Agent’s capabilities by making the application UI, logs, and metrics directly visible and understandable to Codex.
For example, we enabled the application to independently launch for each Git worktree, allowing Codex to run and drive an instance for every code change. We also integrated the Chrome DevTools Protocol into the Agent runtime and created skills for handling DOM snapshots, screenshots, and navigation. This allowed Codex to directly reproduce bugs, validate fix results, and infer UI behavior.
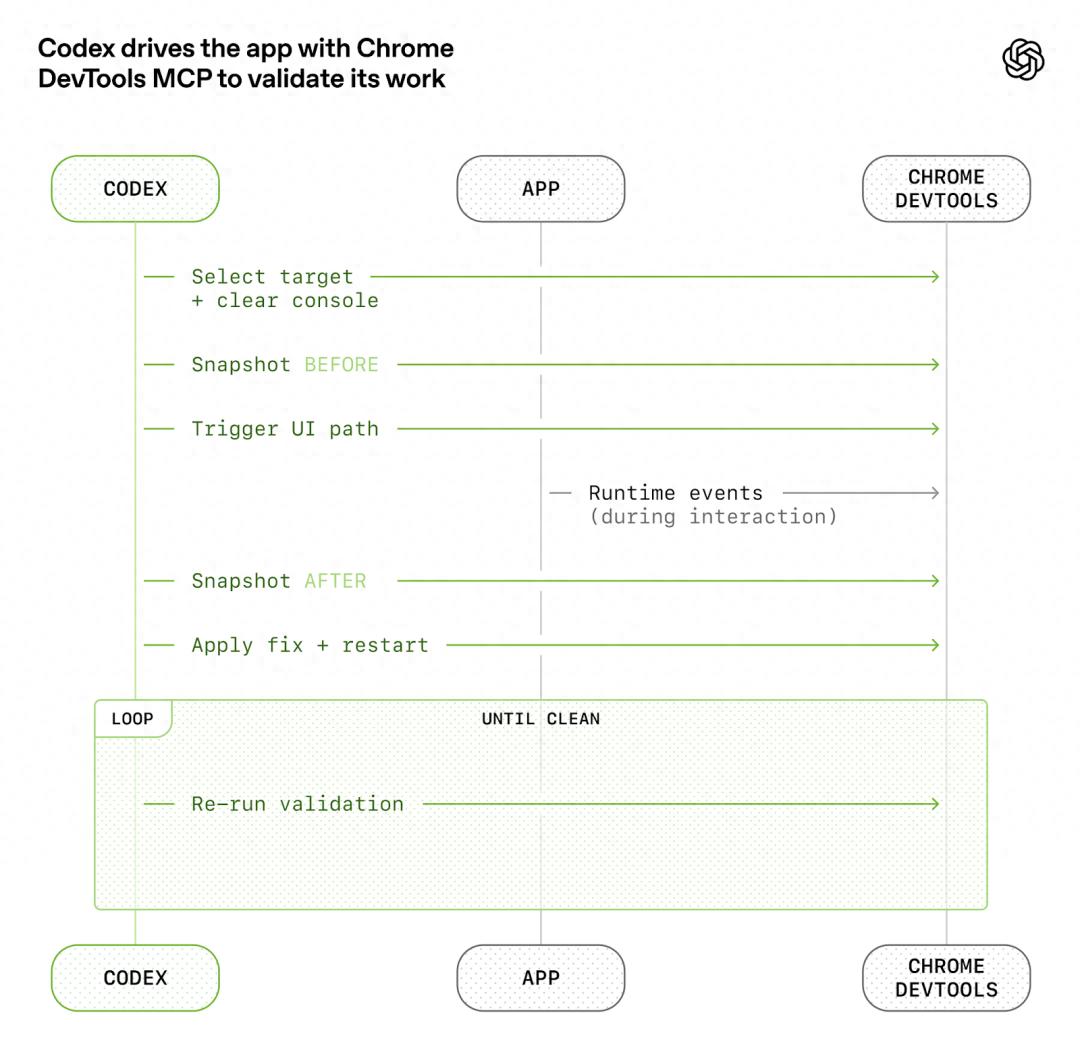
We applied the same approach to observability tools. Logs, metrics, and tracing were exposed to Codex through a local observability stack, which is temporary for any given worktree. Codex runs on a fully isolated version of the application, including its logs and metrics, which are destroyed after the task is completed. The Agent can use LogQL to query logs and PromQL to query metrics. With this context, prompts like “ensure service startup completes within 800ms” or “no Trace Span exceeds 2 seconds in these four key user journeys” become actionable.
We often see a single Codex run processing a task for over six hours (usually while humans are asleep).
Using Repository Knowledge as a Source of Truth
Context management is one of the biggest challenges in enabling the Agent to handle complex tasks. The core lesson we learned is: give Codex a map, not a thousand-page manual.
We tried a “single AGENTS.md large file” approach but quickly failed: 1. Context is a scarce resource: a massive instruction file occupies space needed for task code and related documentation. This can lead to the Agent either missing critical constraints or optimizing towards the wrong goals. 2. Over-guidance equals no guidance: when everything is labeled as “important,” the focus is lost. The Agent ultimately only performs local pattern matching without purposefully understanding the global context. 3. Documentation is prone to decay: a monolithic manual quickly becomes a graveyard of outdated rules. The Agent cannot determine which rules are still valid, and humans are reluctant to maintain it, resulting in the document becoming a trap that misleads the Agent. 4. Hard to verify: such a single large content block cannot be mechanically checked (for coverage, timeliness, ownership, or cross-linking), leading to inevitable architectural drift.
Thus, we treat AGENTS.md as a directory rather than an encyclopedia.
The knowledge base of the code repository exists in a structured docs/ directory and is viewed as the sole source of truth. A brief AGENTS.md (about 100 lines) is injected into the context, primarily serving as a map containing pointers to deeper “sources of truth” scattered throughout.
AGENTS.md
ARCHITECTURE.md
/docs/
├── design-docs/
│ ├── index.md
│ ├── core-beliefs.md
│ └── ...
├── exec-plans/
│ ├── active/
│ ├── completed/
│ └── tech-debt-tracker.md
├── generated/
│ └── db-schema.md
├── product-specs/
│ ├── index.md
│ ├── new-user-onboarding.md
│ └── ...
├── references/
│ ├── design-system-reference-llms.txt
│ ├── nixpacks-llms.txt
│ ├── uv-llms.txt
│ └── ...
├── DESIGN.md
├── FRONTEND.md
├── PLANS.md
├── PRODUCT_SENSE.md
├── QUALITY_SCORE.md
├── RELIABILITY.md
└── SECURITY.md
Design documents are cataloged and indexed, containing verification statuses and a set of core beliefs defining “Agent-first” operational principles. Architectural documents provide a top-level map of domain partitions and package layering. A quality document scores each product area and architectural layer and tracks gaps over time.
Plans are treated as first-class citizens. Lightweight temporary plans are used for minor changes, while complex work is recorded in execution plans, along with progress and decision logs submitted to the repository. Active plans, completed plans, and known technical debts are versioned and managed together, enabling the Agent to work without relying on external context.
This achieves progressive disclosure: the Agent starts from a small, stable entry point and is told where to look for information next, rather than being overwhelmed by a massive amount of information upfront.
We enforce this through mechanical means. Dedicated Linters and CI tasks verify that the knowledge base is up-to-date, correctly cross-referenced, and structurally compliant. A looping “documentation gardener” Agent scans for outdated or stale documents that do not reflect real code behavior and opens fix-related PRs.
Aiming for Agent Readability
As the codebase evolves, Codex’s design decision framework also evolves.
Since the entire repository is generated by the Agent, it was initially optimized for Codex’s readability. Just as the development team aims to enhance code navigability for new engineers, our goal as human engineers is to enable the Agent to infer and understand the complete business domain knowledge directly from the repository itself.
From the Agent’s perspective, any information that cannot be obtained through context at runtime effectively does not exist. Knowledge stored in Google Docs, chat logs, or in people’s brains is inaccessible to the system. Only locally stored, versioned artifacts (such as code, Markdown, Schemas, executable plans) are the entirety of its visible world.
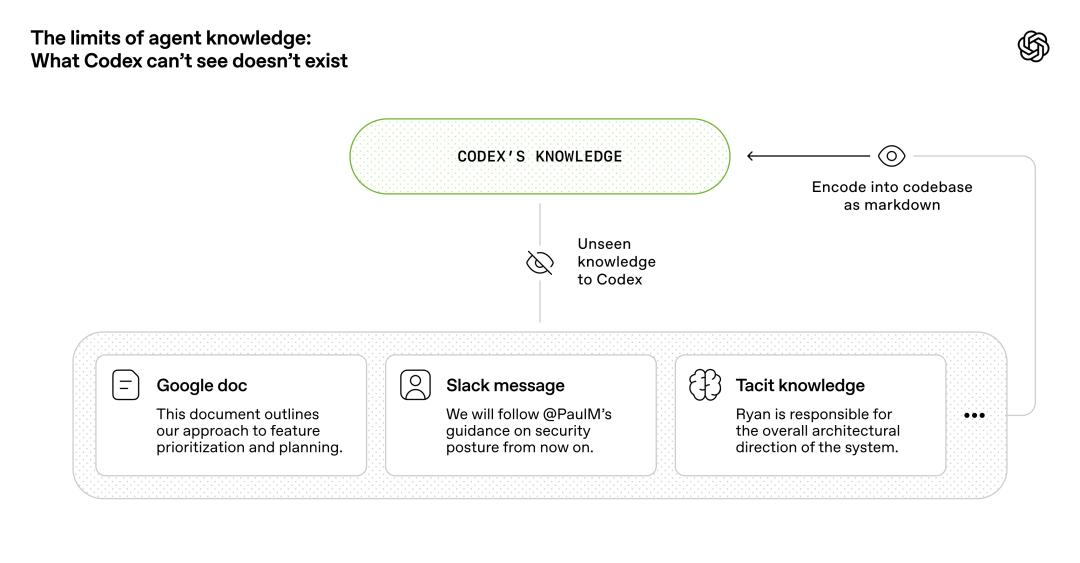
We realized that over time, we needed to push more context into the repository. For example, a Slack discussion that helped the team reach consensus on architectural patterns, if not retrievable by the Agent, is “unreadable”—just as that background is missing for a new employee joining three months later.
Providing Codex with more context means organizing and exposing the right information for the Agent to reason, rather than overwhelming it with a plethora of temporary instructions. Just as you would introduce product principles, engineering norms, and team culture (including preferences for emoji usage) to a new teammate, providing this information to the Agent leads to more consistent outputs.
This thinking clarifies many trade-offs. We prefer dependencies and abstractions that can be fully internalized and reasoned about within the repository. Those often labeled as “boring” technologies tend to be easier for the Agent to model due to their composability, API stability, and high coverage in training sets. In some cases, having the Agent reimplement part of a function is cheaper than bypassing opaque upper-layer behaviors in public libraries. For example, we did not introduce a generic p-limit style package but implemented our own concurrency mapping helper: it tightly integrates with our OpenTelemetry monitoring, has 100% test coverage, and fully meets our runtime expectations.
Transforming more parts of the system into forms that the Agent can directly inspect, validate, and modify not only enhances Codex’s leverage but also benefits other Agents working within the same codebase (e.g., Aardvark).
Enforcing Architecture and Aesthetics
Documentation alone is insufficient to maintain coherence in a codebase entirely generated by Agents. By enforcing “invariants” rather than micromanaging details, we allow the Agent to deliver quickly without compromising the system’s foundation. For instance, we require Codex to perform data format parsing at system boundaries but do not mandate the implementation method (the model seems to prefer Zod, but we have never specified this particular library).
The Agent operates most efficiently in environments where boundaries are strict and structures are predictable. Therefore, we built the application around a rigid architectural model. Each business domain is divided into a set of fixed hierarchies with strictly validated dependency directions and limited allowed connection points. These constraints are enforced mechanically through custom Linters (also generated by Codex!) and structured tests.
The following diagram illustrates this rule: within each business domain (such as “application settings”), code can only depend “forward” along a fixed hierarchy (type definitions → configuration → repository layer → service layer → runtime → UI). Cross-domain concerns (such as authentication, connectors, telemetry, feature flags) enter through a single, clear interface: providers. Any dependencies outside of this are prohibited and enforced mechanically.
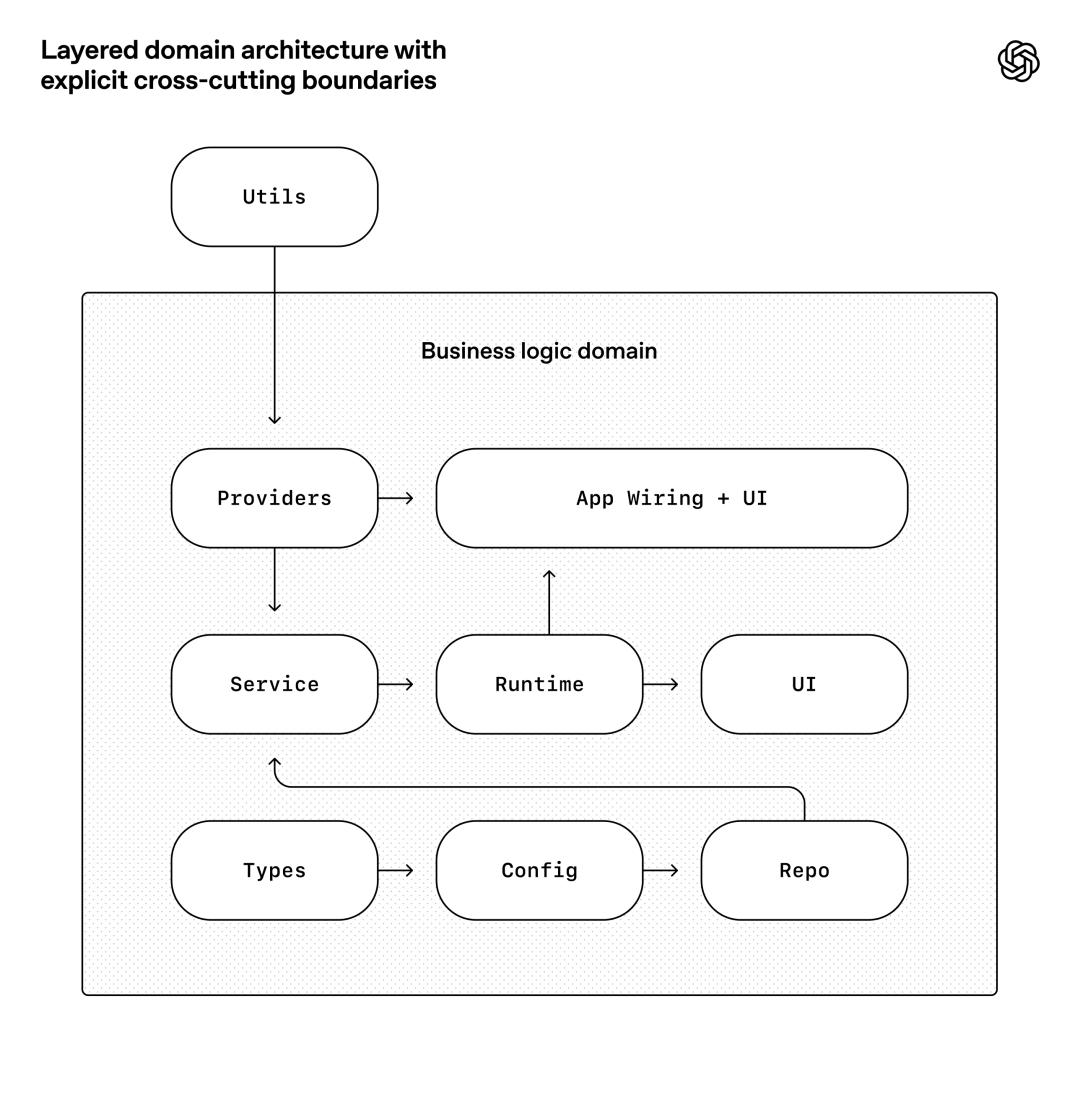
This architecture is typically considered only after having hundreds of engineers. However, when using programming Agents, it becomes a necessary prerequisite: it is these constraints that prevent the system from degrading or drifting architecturally while iterating at high speed.
In practice, we enforce these rules through custom Linters, structured tests, and a small set of “aesthetic invariants.” For example, we statically enforce structured logging, architectural and type naming conventions, file size limits, and reliability requirements for specific platforms. Since the Linters are custom, we can write specific error messages to inject repair instructions directly into the Agent’s context.
In a human-centered workflow, these rules may seem overly rigid or constrained. However, in an Agent environment, they become multipliers of efficiency: once encoded, the rules are immediately applied everywhere.
At the same time, we clearly distinguish where constraints are necessary and where they are not. This is very much like leading a large engineering platform organization: central enforcement of boundaries, with local autonomy allowed. You need to focus intensely on boundaries, correctness, and reproducibility; while within those boundaries, you allow teams (or Agents) significant freedom in expressing solutions.
The resulting code does not always conform to human aesthetic preferences, but that is acceptable. As long as the output is correct, maintainable, and understandable for future Agent runs, it meets the standard.
Human aesthetics will continue to feedback into the system. Review comments, refactor PRs, and user-facing bugs will be transformed into documentation updates or directly encoded into the toolchain. When documentation is insufficient to constrain behavior, we elevate the rules to code.
Increased Throughput Changes Merging Philosophy
As Codex’s throughput increased, many traditional engineering norms became counterproductive.
The blocking merge threshold at runtime is extremely low. The lifecycle of Pull Requests is very short. For occasional test failures, they are typically resolved through subsequent runs rather than indefinitely blocking progress. In a system where Agent throughput far exceeds human attention, error correction is cheap, while waiting is costly.
In a low-throughput traditional environment, this would be irresponsible; but here, it is often the correct trade-off.
The True Meaning of “Agent Generated”
When we say the codebase is generated by Codex Agent, we mean everything in the codebase.
The content produced by the Agent includes:
- Product code and test scripts
- CI configuration and release tools
- Internal developer tools
- Documentation and design history
- Evaluation harnesses
- Review comments and replies
- Scripts for managing the repository itself
- Definition files for production environment dashboards
Humans still maintain overall control; the abstraction level of work has just changed. Our current tasks involve prioritizing, translating user feedback into acceptance criteria, and ultimately ensuring the results. When Agent development encounters obstacles, it serves as a clear signal to remind us to reflect: what is missing in the system? Is it insufficient tools, unstable guardrails, or erroneous documentation? Once the root cause is identified, we inject this feedback into the repository while still insisting that Codex write the repair solutions itself.
Agents directly use our standard development tools. They obtain review feedback, make inline replies, push updates, and often autonomously squash and merge their own PRs.
Continuously Increasing Autonomy
As more development loops (testing, validation, review, feedback processing, and fault recovery) are directly encoded into the system, the repository recently crossed a milestone: Codex can now end-to-end drive the development of new features.
With just a prompt, the Agent can now autonomously complete the following process:
- Validate the current state of the codebase
- Reproduce the reported bug
- Record a video demonstrating the failure process
- Implement a fix
- Validate the fix results by operating the application
- Record a second video demonstrating the fix effect
- Open a Pull Request
- Respond to feedback from Agents and humans
- Detect and fix build failures
- Only escalate when human judgment is needed
- Merge changes
This behavior heavily relies on the specific structure and toolchain of this repository. Without similar investments, one should not assume this capability can be directly generalized, at least not yet.
Increasing Entropy and Garbage Collection
Complete Agent autonomy also brings new challenges. Codex tends to replicate existing patterns in the repository—even those that are unbalanced or suboptimal. Over time, this inevitably leads to architectural drift.
Initially, humans manually addressed this issue. Our team was fixed on cleaning up “AI debris” every Friday (20% of the week’s work time). Unsurprisingly, this model was not scalable.
To tackle these issues, we chose to write the so-called “golden rules” directly into the code repository and establish a periodic cleanup mechanism. These principles are mechanized rules with clear assertions aimed at ensuring the codebase remains clear and consistent during subsequent Agent runs. Specific practices include: first, we prefer using shared toolkits over hand-written helper functions to centralize management of those invariants; second, we reject “by chance” data probing, requiring validation at boundaries or relying on strongly typed SDKs to prevent the Agent from sampling guessed data shapes to write code. We regularly run a set of Codex background tasks specifically to scan for code that deviates from the rules, update quality scores, and open targeted refactor PRs. Since these rules are very clear, most PRs can be reviewed and automatically merged within a minute.
This mechanism operates like “garbage collection.” Technical debt is like high-interest loans: continuous small repayments are almost always better than letting it compound and ultimately resolving it in painful explosive cleanups. Once human aesthetics are captured, they will be continuously enforced into every line of code. This also allows us to timely identify and eliminate bad patterns in our daily work rather than letting them fester in the codebase for days or weeks.
Areas We Are Still Exploring
So far, this strategy has performed well in the release and promotion of OpenAI’s internal products. By building real products for real users, our investments serve real needs and guide the system towards long-term maintainability.
Currently, we are still unclear how architectural coherence will evolve over a span of years in a system entirely generated by Agents. We are still exploring where human judgment can yield the greatest leverage and how to translate that judgment into rules that can be codified and yield compounding effects. Meanwhile, how this system will evolve as model capabilities continue to enhance remains an unknown.
But one thing is already clear: building software still requires rigorous discipline, but this discipline is no longer reflected in code writing; rather, it is embodied in the construction of the “scaffolding.” Tools, abstractions, and feedback loops that maintain coherence in the codebase are becoming increasingly important.
Our most daunting challenge now lies in how to design environments, feedback loops, and control systems. Only by doing so can we help the Agent achieve our goal of building and maintaining complex and reliable software at scale.
As Agents like Codex take on an increasing share of the software lifecycle, these issues will become critical. We hope these early lessons can help you think about where to invest your energy, allowing you to create products more purely.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.