Introduction
The large model industry is undergoing a crucial transition from parameter competition to deliverable intelligence. The launch of GLM-5 not only signifies a major breakthrough in open-source models but also shifts the competitive focus from mere code generation to comprehensive engineering delivery capabilities. This article delves into three major migration trends facing the industry, the current bottlenecks in delivery, and how Agentic Engineering will reshape enterprise productivity over the next 3-5 years.

Industry Background: Shifting from Parameter Competition to Deliverable Intelligence
In the past two years, I have observed a clear shift in the focus of the large model industry, particularly three significant migrations:
- From General Conversation to Vertical Implementation: Enterprises are increasingly paying for models that can complete tasks rather than just engage in conversation.
- From Single Task Capability to Long-Term Tasks: The marginal value of writing a line of code or editing a phrase is declining; the value of models that can manage tasks across files, tools, and stages is on the rise.
- From Closed Source Monopoly to Open Source Competition: Especially in the domestic market, under external restrictions and cost constraints, local solutions that are “controllable, deployable, and customizable” are becoming the default option. Reuters also mentioned that Zhipu released GLM-5 (open-source) emphasizing programming and long-term agent capabilities, highlighting its training on domestic chips like Huawei’s Ascend, reflecting a strategic context of supply chain and computing power independence.
Thus, the significance of GLM-5 lies not in how much its metrics have improved, but in its clear shift of the main battlefield from “writing code” to “engineering delivery (Agentic Engineering).” The official documentation even positions it as designed for Agentic Engineering.
Current Issues: Stuck Between Usability and Deliverability
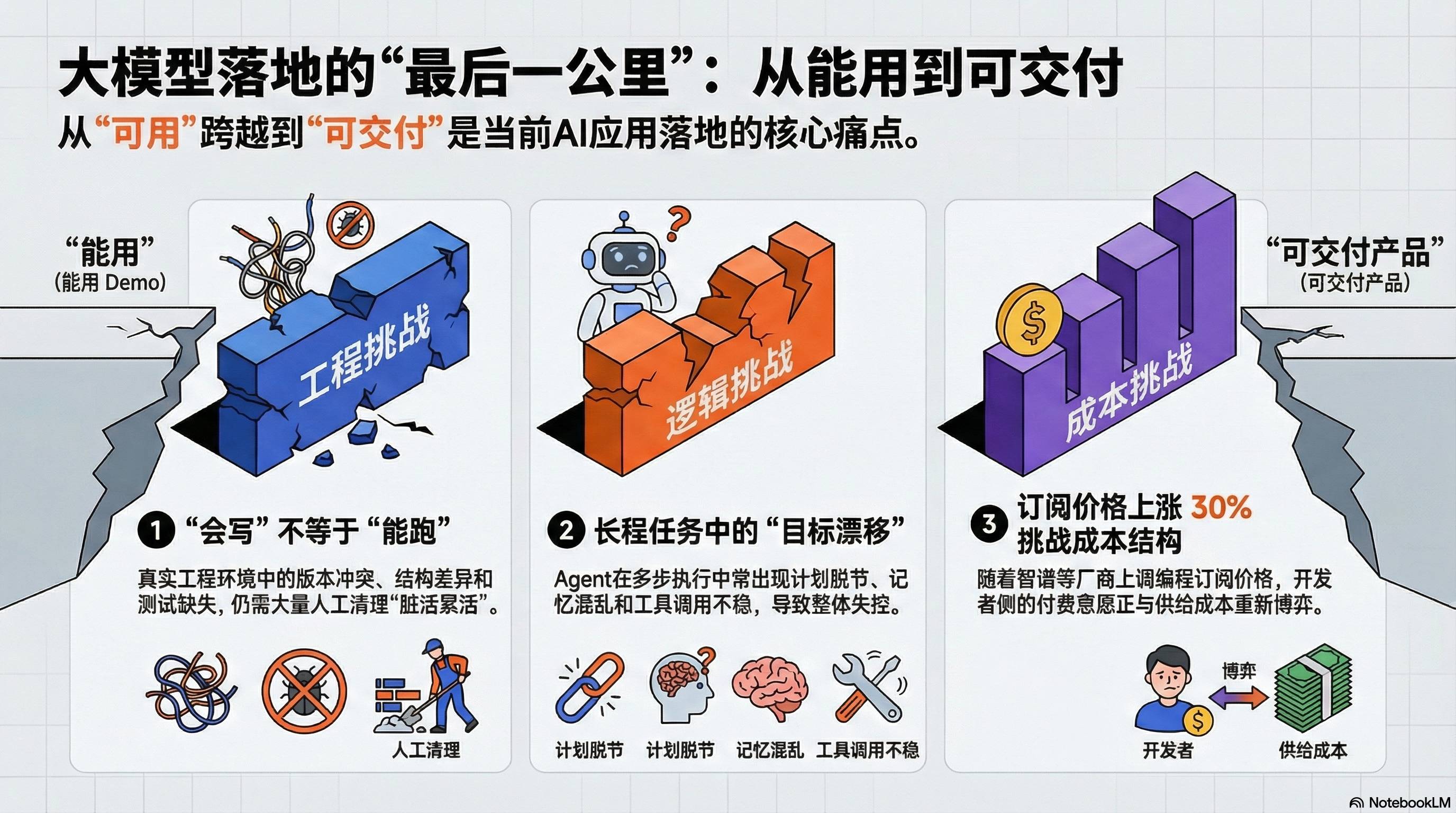
If we break down enterprise expectations for large models into three levels: usable (can answer) — controllable (can answer according to rules) — deliverable (can complete tasks and be accepted), the most significant bottleneck currently lies in the third level.
-
“Can Write” Does Not Equal “Can Run” Many models appear strong in demos, but once in real projects, issues arise: version mismatches, inconsistent project structures, lack of testing, and missing boundary conditions. Ultimately, engineers are left to fill in the gaps to make AI products runnable and acceptable.
-
Goal Drift in Long-Term Tasks When agents span multiple steps, a common problem is that they drift further off course: plans and execution become disconnected, memory becomes confused, tool calls become unstable, and local optimizations derail the overall process. GLM-5 positions “long-term agent tasks” as a core selling point, targeting these pain points.
-
Cost Structure Begins to Bite Back Against Scaled Applications As applications transition from pilot to regular high-frequency use, inference costs and engineering efficiency are no longer “optimization items” but hard constraints. Concurrently, commercial pressures are rising: Reuters reported that Zhipu raised the subscription price for GLM programming (by at least 30%) due to increased demand, indicating a recalibration between developers’ willingness to pay and supply costs.
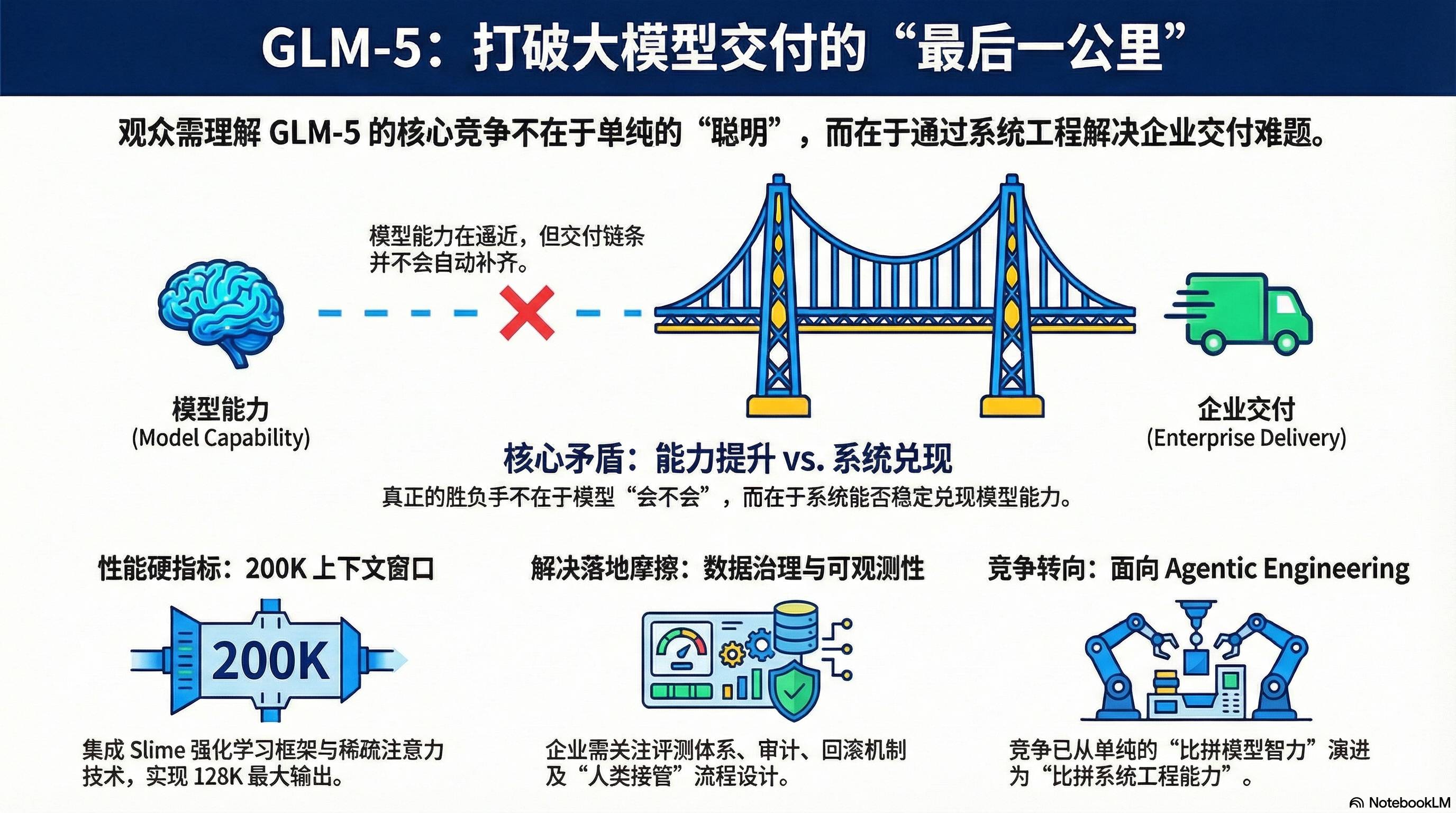
Core Contradiction: Open Source Approaching Top Closed Source vs. Systemic Barriers to Real Delivery
My core judgment about GLM-5 is that it represents a path of “stronger foundation + more engineering-oriented post-training + lower deployment costs” to penetrate delivery barriers. However, the real determinant of victory often lies not in whether the model can perform, but in whether the system can reliably deliver the model’s capabilities.
This can be broken down into two opposing forces:
- Capability Side Accelerating: GLM-5 emphasizes parameter scale, data scale, asynchronous reinforcement learning frameworks (“Slime”), and sparse attention (integrating DeepSeek Sparse Attention) to enhance long context efficiency and deployment costs, providing engineering metrics like a 200K context window and a maximum output of 128K.
- Delivery Side Friction is More Real: When enterprises implement, the true determinants of success are the evaluation systems, toolchains, permissions/audits, knowledge bases and data governance, rollback mechanisms, observability (understanding why errors occur and where), and the design of “human takeover” processes.
In summary, while model capabilities are approaching, the delivery chain will not automatically fill in the gaps. GLM-5’s focus on “Agentic Engineering” is essentially shifting competition from “being smarter” to “being better at system engineering.”
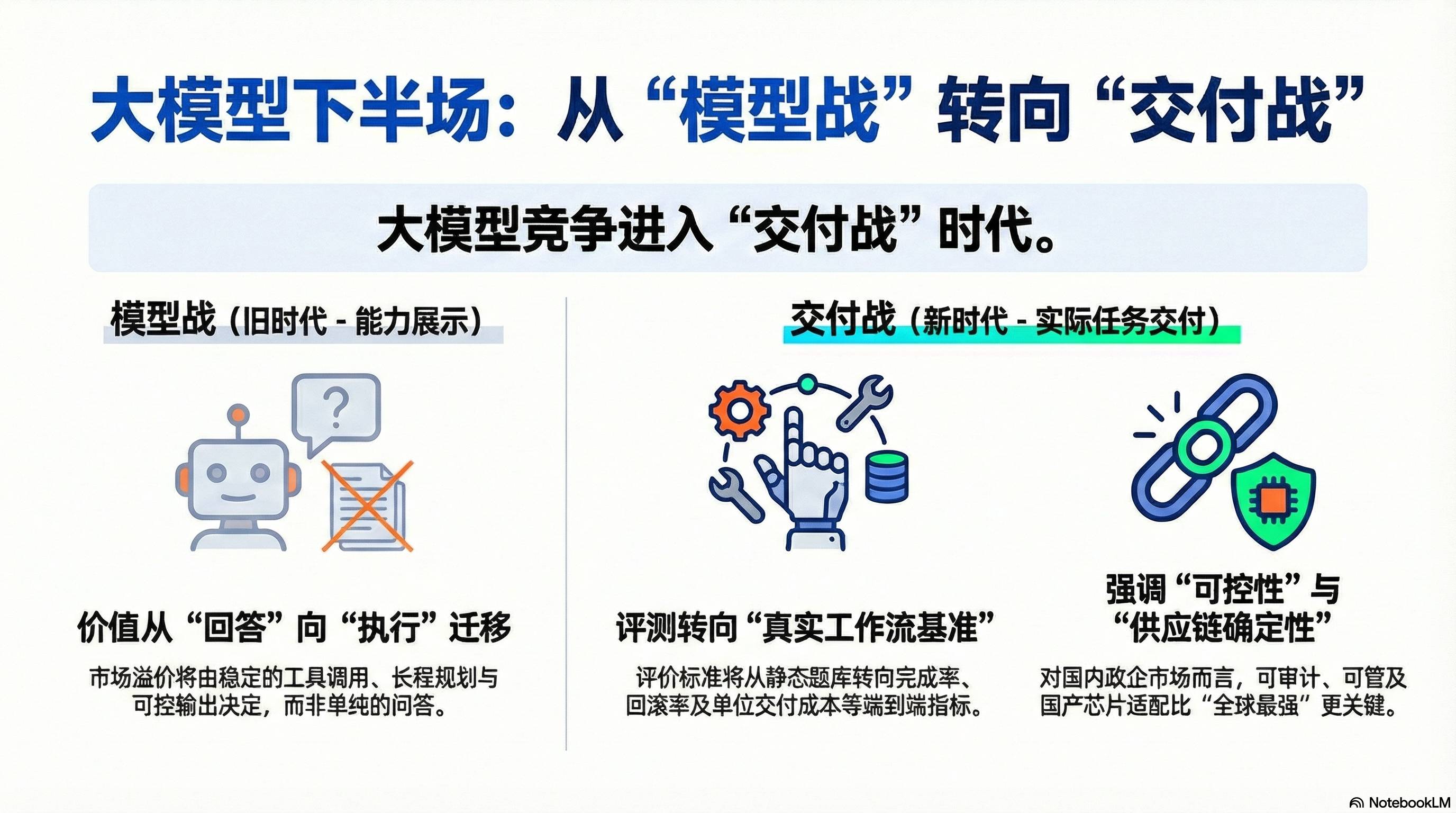
Trend Predictions: Large Model Competition Will Shift from “Model Wars” to “Delivery Wars” in the Next Two Years
In light of releases like GLM-5, I prefer to summarize the upcoming changes over the next two years into three trends:
-
Models Will Be Repriced, Shifting Value from “Answering” to “Executing” As open-source models continuously push the limits in coding/agent evaluations (GLM-5 claims to have achieved the highest scores in SWE-bench-Verified, Terminal Bench 2.0, and emphasizes being the top in Agent evaluations like BrowseComp, MCP-Atlas, τ²-Bench), the market will gradually view “being able to answer correctly” as a threshold rather than a source of premium. The true premium will come from more stable tool calls, fewer hallucinations, stronger long-term planning and self-checking, and more controllable output structures.
-
Evaluations Will Shift from “Static Question Banks” to “Real Workflow Benchmarks” Traditional benchmarks can only represent a slice of capability, while Agentic engineering requires end-to-end metrics: completion rates, rollback rates, human intervention counts, average repair cycles, and unit delivery costs. GLM-5 brings “complex system engineering and long-term task execution” to the forefront, essentially betting that the next generation of evaluation standards will be more aligned with real workflows.
-
The Domestic Market Will Emphasize “Deployability, Controllability, and Supply Chain Certainty” Reuters noted that GLM-5 was trained using domestic chips, which is not just a technical narrative but a commercial one: for government and heavily regulated industries, “controllable, manageable, and auditable” is often more important than being the “world’s strongest.”
Future Projections: Where Will Routes Like GLM-5 Lead the Industry in 3-5 Years?
In this section, I want to discuss “industry evolution”: focusing not on single-point metric increases but on how the competitive landscape and product forms change.
-
Stage 1 (Next 12 Months): Agentic Coding Becomes the Default Working Method for Developers Developer scenarios have the clearest demands and the most direct ROI. GLM-5 clearly strengthens programming and engineering delivery, providing support for long contexts and tool calling capabilities (Function Call, structured output, context caching, etc.). However, the key to victory in this stage lies not just in the model itself but in IDE/CLI integration, repository-level understanding, test generation and auto-repair, and integration with enterprise coding standards/permission systems.
-
Stage 2 (1-3 Years): Enterprise “Business Agents” Move from Pilot to Scale, While Undergoing a “Hallucination Governance” and “Responsibility Attribution” Restructuring When agents truly engage with business systems (work orders, CRM, finance, procurement), hallucinations are no longer just an experience issue but a risk issue. Enterprises will demand more rigorously:
- Traceability: What data was referenced at each step, what tools were called
- Auditability: Minimal permissions, data remaining within domains
- Rollback: Erroneous actions can be undone This will force platform layers (not just individual models) to form moats: observation, governance, sandboxing, approval flows, and red team testing.
-
Stage 3 (3-5 Years): Base Models Tend Towards “Semi-Commodity”, Differentiation Shifts to “Industry Workflows + Data Flywheels + Organizational Adaptation” If open-source models continue to approach top closed-source models, enterprises will ultimately treat the base as interchangeable components. At that point, the true differentiators will be three things:
- Structured accumulation of industry knowledge (knowledge bases, graphs, processes, and rules)
- Real task data feedback loops (what tasks failed, what failure modes exist, how to retrain/realign)
- Institutionalized “human-machine division of labor” (who approves, who reviews, who is responsible for errors) From this perspective, the strategic value of GLM-5 is not how closely it resembles a top closed-source model, but how it pulls domestic competitors into a more realistic battlefield: who can turn agents into deliverable productivity systems. This also explains why media reports strongly associate it with “complex system engineering” and “long-term agents” while emphasizing its approach to closed-source top-tier experiences.
Conclusion: My Independent View on GLM-5
What deserves the most attention about GLM-5 is not that “open source has caught up with whom,” but that it advances the industry narrative from “chatting more like humans” to “delivering more like teams.” When models set “writing engineering” as their primary goal, the industry will be forced to acknowledge a fact: the future competition among large models is fundamentally a competition in system engineering. The model is merely the engine; what truly determines experience and value is the entire transmission system, braking system, and dashboard.
If you are working on large model products or enterprise implementations, I recommend shifting your evaluation focus from “single response effectiveness” to three types of metrics:
- End-to-End Delivery Rate (task completion and acceptance)
- Human Intervention Costs (how many times intervention is needed)
- Failure Controllability (can errors be located, rolled back, and reviewed)
Whoever can establish a long-term advantage in these three areas is more likely to win in the upcoming “delivery wars” over the next 3-5 years.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.