Claude Opus 4.7 Launch
On April 17, 2026, Anthropic launched its next-generation flagship model, Claude Opus 4.7.
This model shows significant improvements in advanced software engineering compared to Opus 4.6, especially in handling complex tasks. Its high-resolution image processing capability has increased to over three times that of previous Claude models. Additionally, Claude Code has introduced a new /ultrareview code review command, which initiates a review session to check code changes line by line.
Users report that they can confidently assign the most challenging coding tasks to Opus 4.7. The model can rigorously handle complex long-running tasks, accurately follow instructions, and independently verify outputs before reporting results.
Starting today, Opus 4.7 is available across all Claude products and APIs, including Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. Pricing remains the same as Opus 4.6: $5 per million tokens for input (approximately 34 RMB) and $25 per million tokens for output (approximately 170.5 RMB). Developers can access it via the Claude API.
The rapid updates to Claude have left many users amazed, with comments flooding in with memes expressing surprise at the new release.
Enhanced Instruction Adherence and Multimodal Support
In testing, Claude Opus 4.7 has excelled in several areas, significantly surpassing Opus 4.6:
-
Instruction Adherence: Opus 4.7 shows a marked improvement in following instructions. While previous models might loosely interpret or skip parts of instructions, Opus 4.7 executes them literally. Users should adjust their prompts and application frameworks accordingly.
-
Enhanced Multimodal Support: Opus 4.7 has improved visual capabilities for high-resolution images, accepting images with a maximum long side of 2576 pixels (about 3.75 million pixels), which is over three times that of earlier Claude models. This opens up vast possibilities for multimodal applications that rely on fine visual details, such as recognizing dense screenshots while operating a computer, extracting data from complex charts, and performing pixel-level design work.
-
Practical Work: In addition to achieving top scores in financial agent evaluations, internal tests by Anthropic show that Opus 4.7 is a more effective financial analyst than Opus 4.6, producing more rigorous analyses and models, and more professional presentations, allowing for tighter cross-task integration. Opus 4.7 also achieved optimal scores in third-party economic value knowledge work evaluations in fields like finance and law.
-
Memory Capability: Opus 4.7 exhibits stronger memory capabilities based on file system usage. It can remember important notes during long-term, multi-session work and leverage these memories to advance new tasks, thus reducing the need for prior context.
Opus 4.7 has received positive feedback from early testers. Clarence Huang, VP of technology at financial software company Intuit, noted that the model can autonomously identify logical errors during the planning phase and operates significantly faster than its predecessor. Igor Ostrovsky, CTO of AI programming tool company Augment Code, believes that Opus 4.7 excels in managing automation processes, CI/CD (Continuous Integration and Deployment), and long task workflows, actively providing its judgments rather than merely echoing user inputs.
Leading in Multiple Evaluations
Significant Improvements in Biological and Document Reasoning
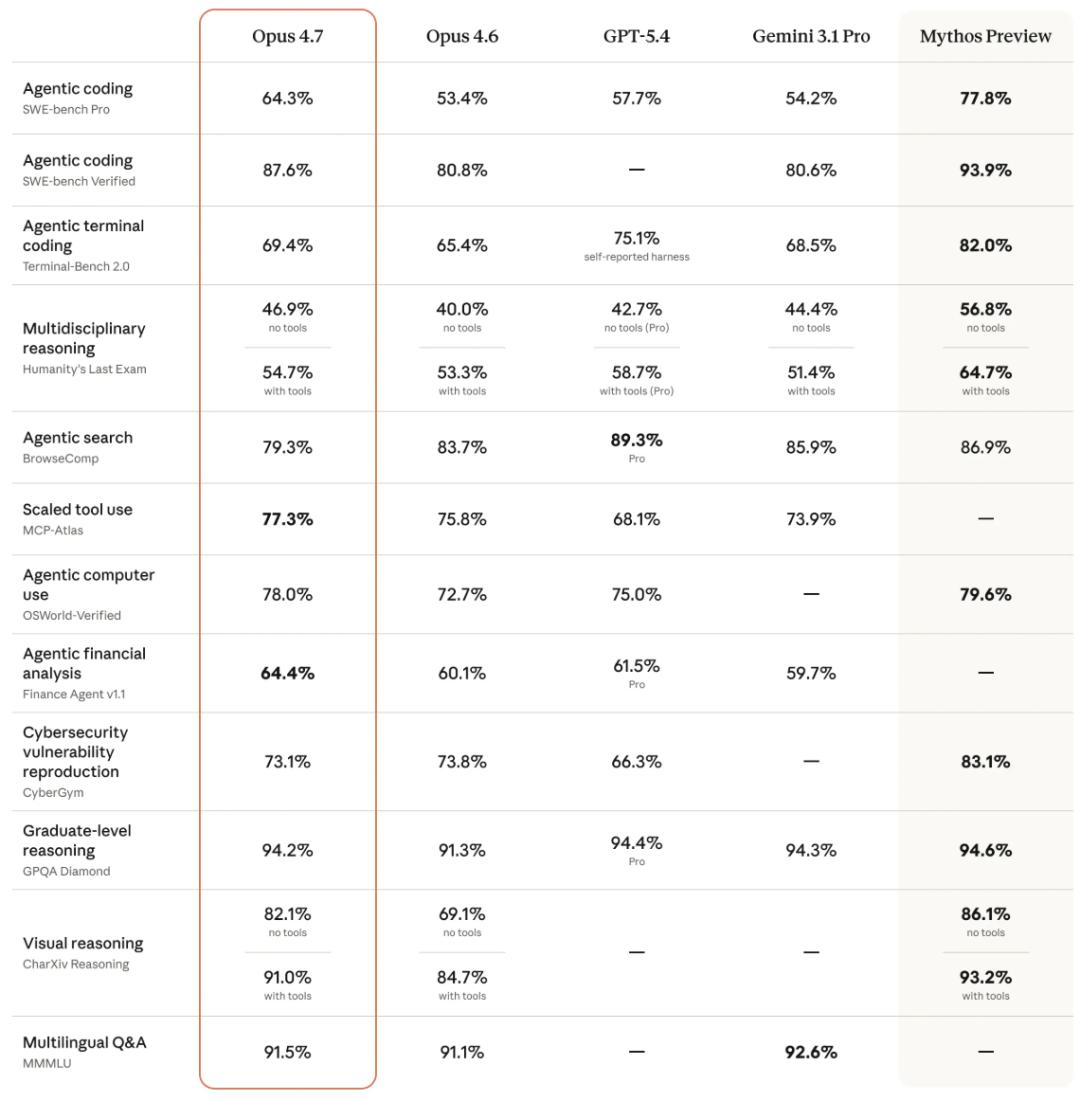
Anthropic conducted pre-release testing of Opus 4.7 across various fields, comparing it with Opus 4.6, GPT-5.4, and Gemini 3.1 Pro.
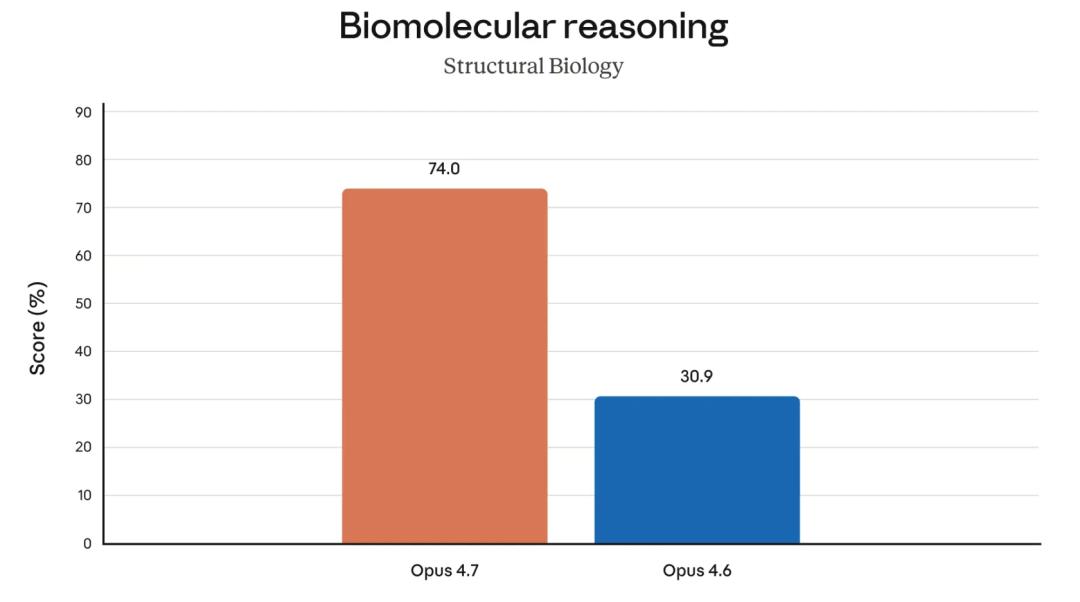
Biological reasoning saw the most significant progress, with Opus 4.7 scoring 74.0%, compared to Opus 4.6’s 30.9%, marking a 1.4 times improvement.
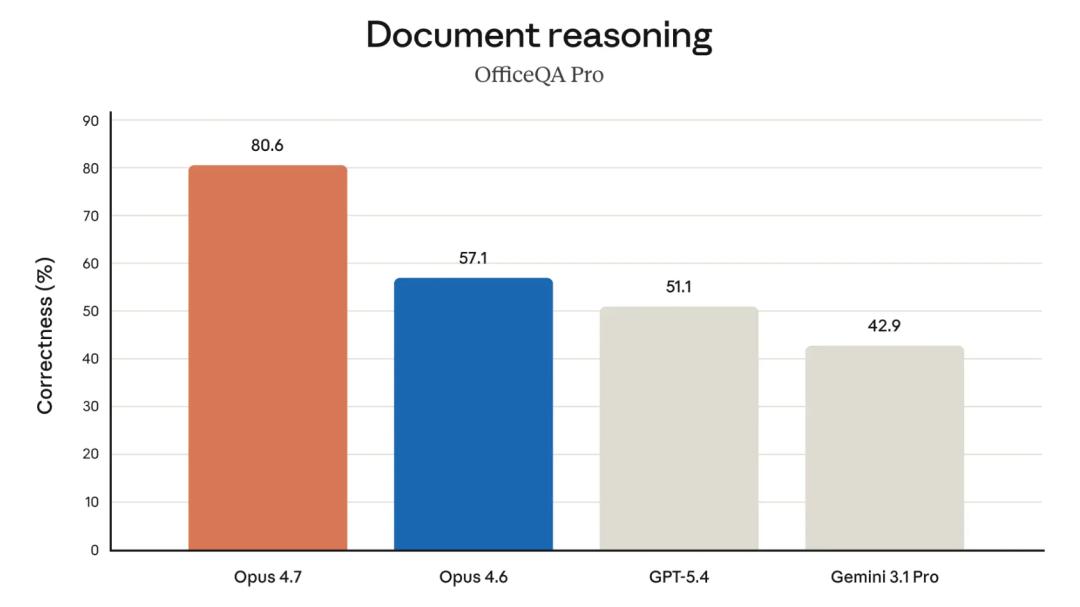
In document reasoning, Opus 4.7 scored 80.6%, far surpassing Opus 4.6’s 57.1%, and significantly outpacing GPT-5.4 (51.1%) and Gemini 3.1 Pro (42.9%), making it one of the most notable projects in the comparison.
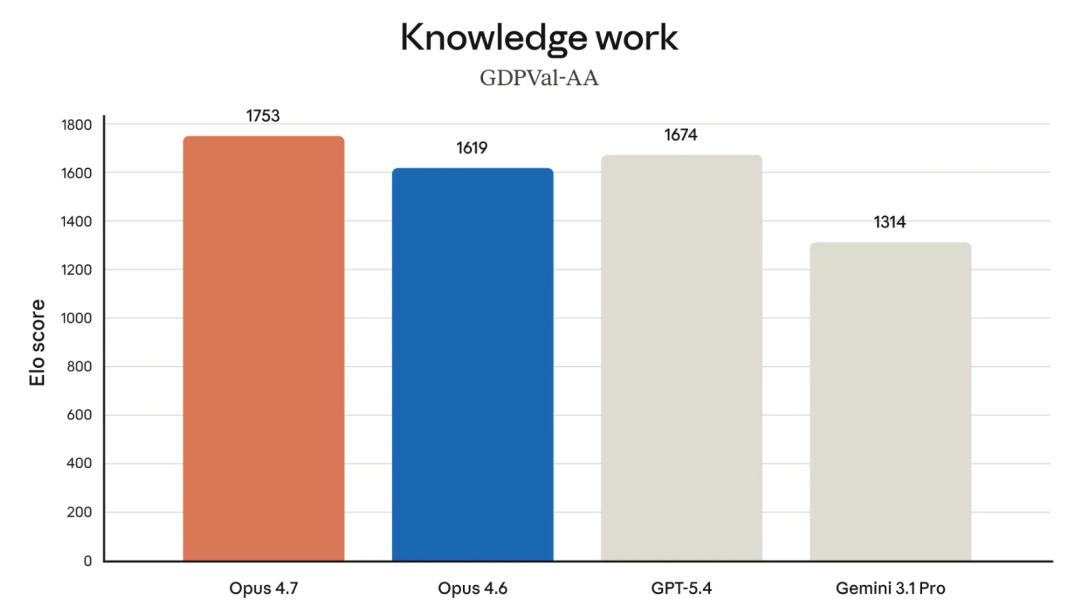
In knowledge work, Opus 4.7 ranked first with an Elo score of 1753, clearly ahead of GPT-5.4 (1674), Opus 4.6 (1619), and Gemini 3.1 Pro (1314).
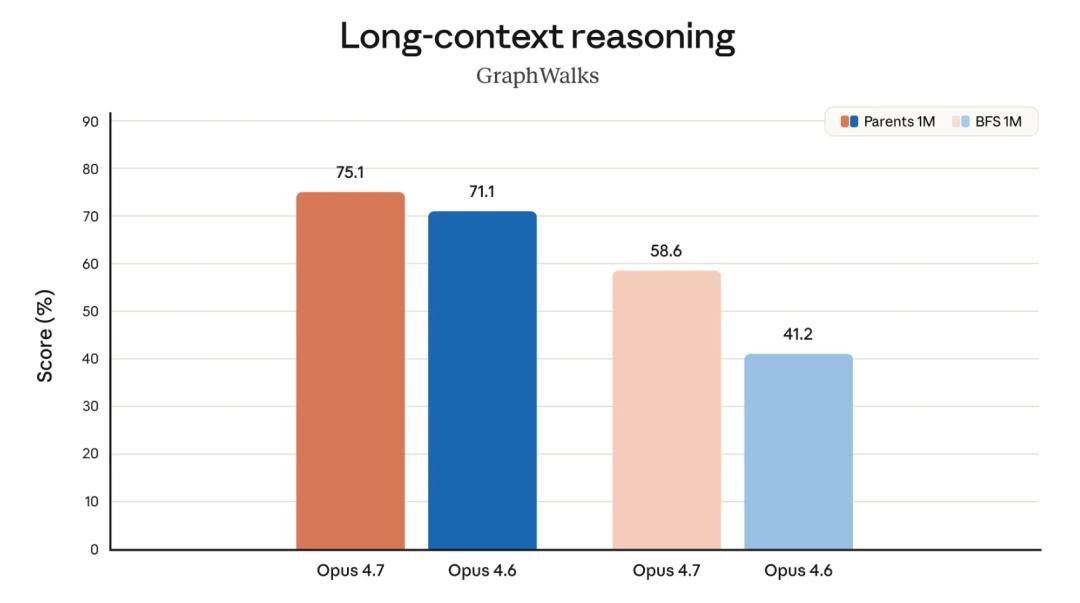
For long context reasoning, during simpler parent node lookup tasks (Parents 1M), Opus 4.7 scored 75.1%, while Opus 4.6 scored 71.1%. However, in more challenging breadth-first search tasks (BFS 1M), Opus 4.7 scored 58.6%, compared to Opus 4.6’s 41.2%, showing a 17-point gap. The more difficult the task, the more pronounced the model’s improvement.
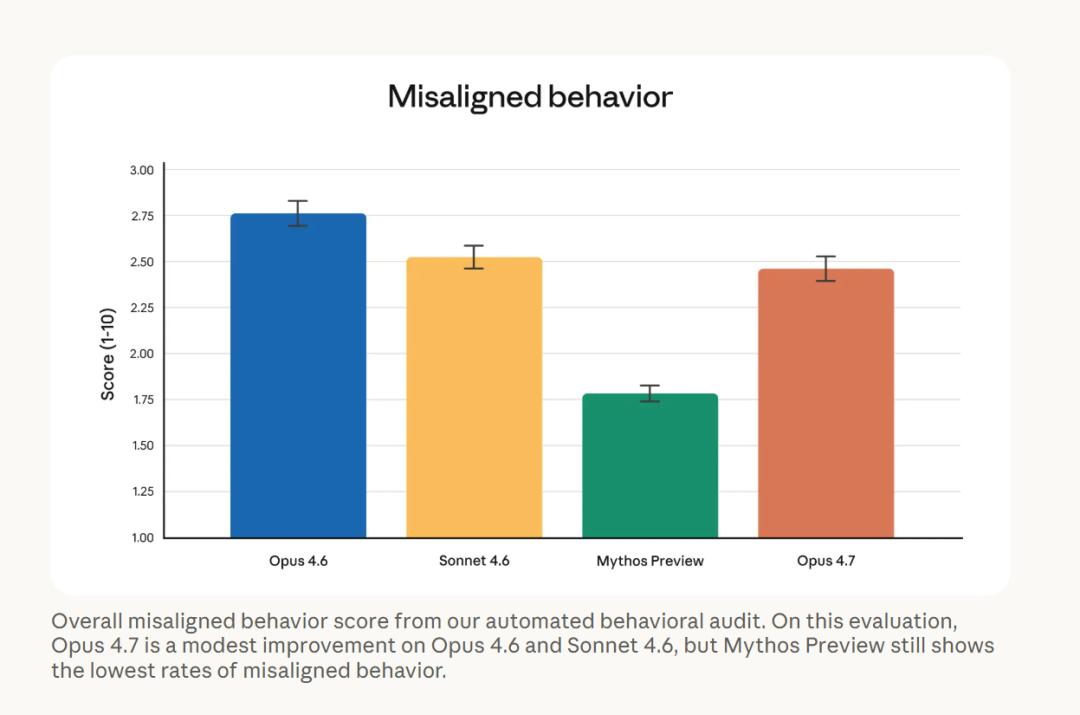
In terms of safety and alignment, Anthropic also released the misalignment behavior scores for each model. Opus 4.7’s misalignment behavior score is approximately 2.47 (with a lower score being better), slightly better than Opus 4.6’s 2.75, but still significantly behind Mythos Preview’s 1.78.
Overall, Opus 4.7’s safety performance is similar to that of Opus 4.6, with a low proportion of deceptive, flattering, and colluding behaviors with abusers. Anthropic commented, “Opus 4.7 is generally well-aligned and trustworthy, but its behavior is not entirely ideal.” Currently, the best alignment performance is from Mythos Preview, which has not yet been fully opened.
Other Updates: New xhigh Level and Review Command
Task Budget in Public Beta
In addition to Opus 4.7 itself, Anthropic has also launched several feature updates.
In terms of reasoning levels, a new xhigh (extra high) level has been added, positioned between the existing high and max levels, allowing users finer control over reasoning depth and response speed. The default reasoning level for Claude Code has been upgraded to xhigh.
For APIs, the task budget feature has entered public beta, allowing developers to guide Claude on how to allocate token consumption during long tasks.
In Claude Code, the /ultrareview command has been added, which, when input, will initiate a dedicated review session to check code changes line by line and mark bugs and design issues. Pro and Max users each receive three free experiences. Additionally, the Auto mode has been expanded to Max users, where Claude can autonomously make operational decisions to reduce manual confirmation interruptions.
Caution: Opus 4.7 May Use More Tokens
But Generates Higher Quality Outputs
Opus 4.7 is a direct upgrade from Opus 4.6, but there are two notable changes affecting token usage.
First, the text processing method has been updated, leading to a potential increase of up to about 35% in token consumption for the same input. Second, the model will engage in more thinking at higher reasoning levels, particularly in subsequent rounds of Agent scenarios, resulting in increased output tokens. Users can manage consumption by adjusting reasoning levels, setting task budgets, or requesting more concise outputs in prompts.
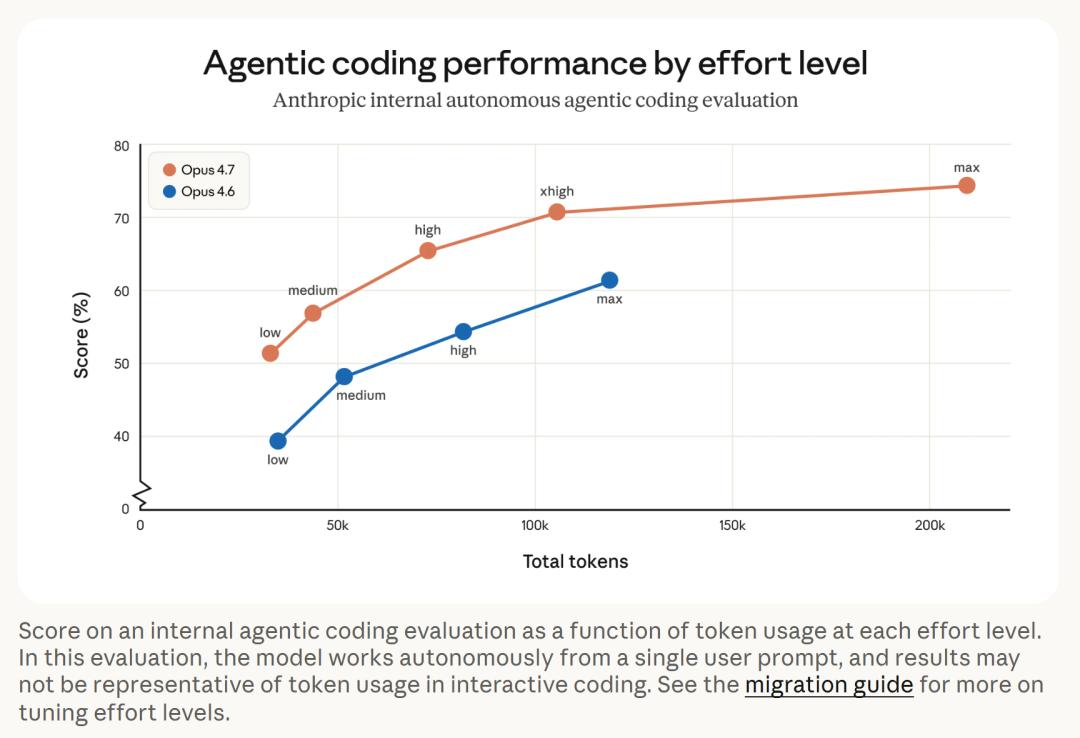
From the Agent programming evaluation chart, Opus 4.7 achieved higher scores with fewer tokens at each reasoning level. For instance, Opus 4.7 consumed about 100,000 tokens at the xhigh level while scoring over 70%, whereas Opus 4.6 consumed about 130,000 tokens at the max level, barely exceeding 60%. However, this evaluation involved the model working autonomously based on a single prompt, and the results may not represent actual token consumption in interactive programming.
Conclusion: More Accurate and Versatile
Increasing Competition Ahead
According to data released by Anthropic, Opus 4.7 shows tangible improvements in programming, document reasoning, biological reasoning, and token efficiency. However, evaluations are still evaluations, and actual performance needs further validation in real-world scenarios.
With the release of Opus 4.7, it will be interesting to see what new moves OpenAI will make next, and whether the long-awaited DeepSeek will release a new model by the end of the month, intensifying competition among large model vendors.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.