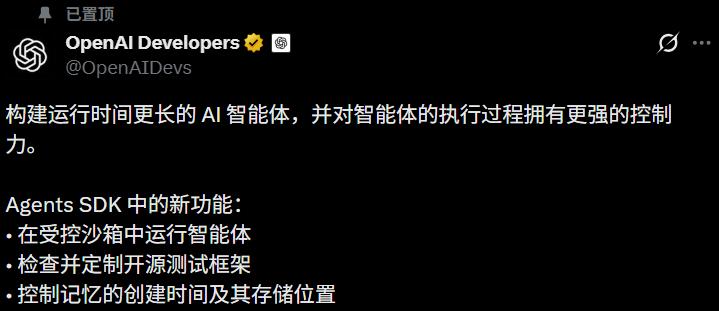
OpenAI has made a significant move by completely rewriting the Agents SDK architecture.
Native harness, native sandbox, Codex-level file system tools, and one-click integration with seven leading sandbox vendors.

In early March, when GPT-5.4 was launched with native computer use capabilities, developers expressed concerns about the framework needed to run the agent safely on various computers. OpenAI has now addressed this gap.
In summary, OpenAI has transformed the Agents SDK from a “toy for chatbots” into a “foundation for production-grade agents”. The harness manages control flow, model invocation, tool routing, and pause/resume functions, while the sandbox handles file reading/writing, dependency installation, and code execution, achieving a complete decoupling.
This move also significantly impacts third-party agent frameworks like LangChain, CrewAI, and LangGraph, as OpenAI has now built the foundational layer, visibly narrowing the space available for third-party solutions.
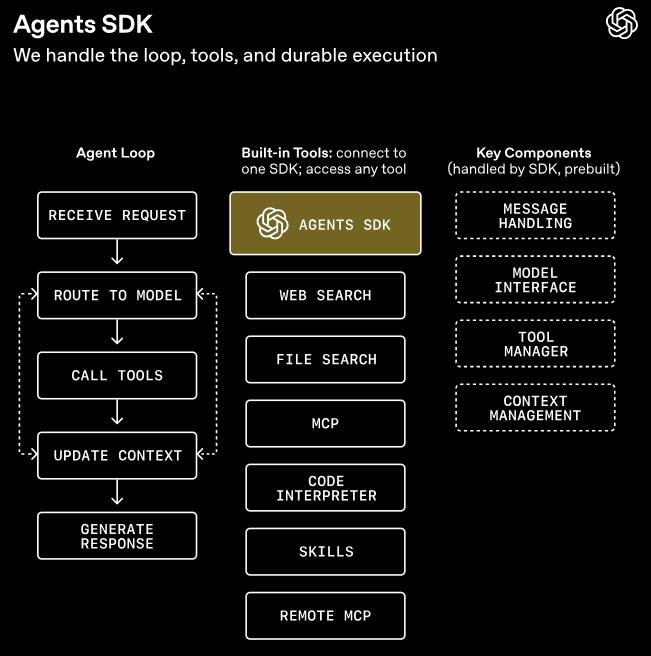
From ‘Chatbot Toy’ to Production-Grade Foundation
Before discussing the upgrade, it’s essential to understand what the original Agents SDK looked like. In March 2025, OpenAI first launched the Agents SDK, emphasizing its lightweight nature and minimal abstraction, allowing it to run with just a few lines of Python code. However, this version was primarily designed for chatbot scenarios.
Over a year, the model’s capabilities have dramatically improved, able to run for hours, days, or even weeks. Consequently, the original SDK designed for chatbots became outdated.
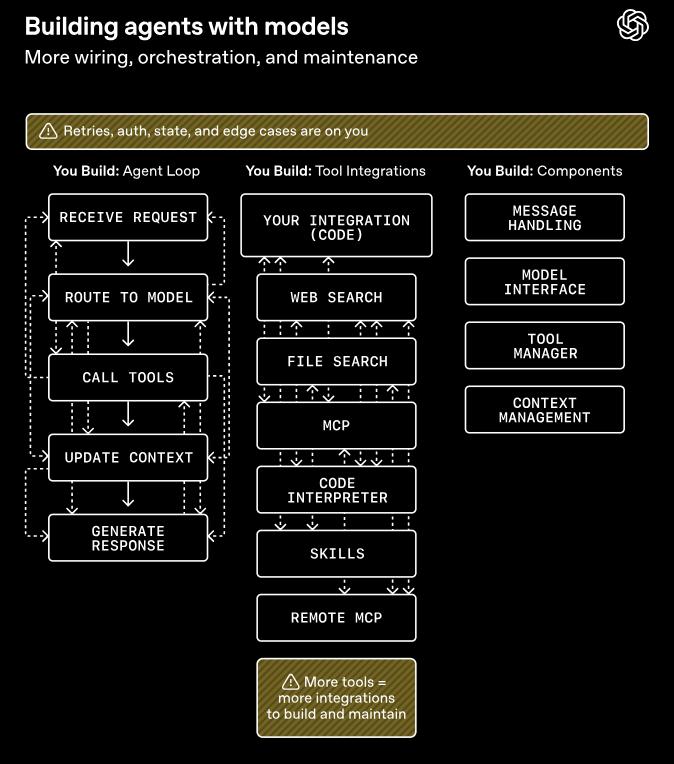
The recent rewrite mainly accomplished two things:
First, it provided the model with a complete runtime framework—harness.
The SDK now includes configurable memory, orchestrated perception sandboxing, Codex-like file system tools, tool invocation via MCP, progressive information disclosure through skills, customizable commands via AGENTS.md, code execution with shell tools, and file editing with apply patch tools—all natively supported.
Developers familiar with Claude Code and Codex will recognize this list. OpenAI has effectively productized the best practices and lessons learned from Codex over the past year into the SDK.
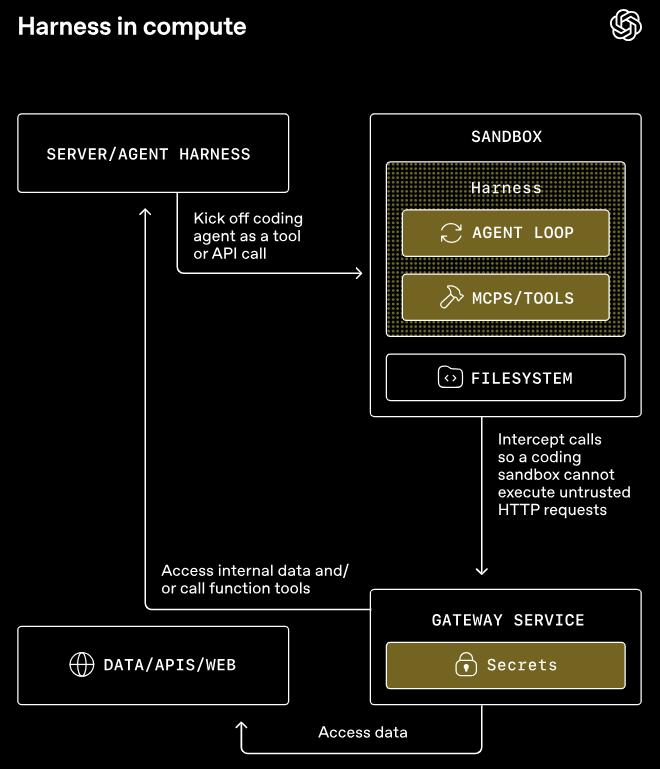
Second, it completely separated harness from compute.
The harness operates within your trusted infrastructure, managing model invocation, approval, tracking, and runtime status. Compute is an independent sandbox responsible for file reading/writing, command execution, package installation, and output generation.
The interface between the two layers is standardized, ensuring that API keys and sensitive credentials do not enter the environment where the model-generated code is executed.
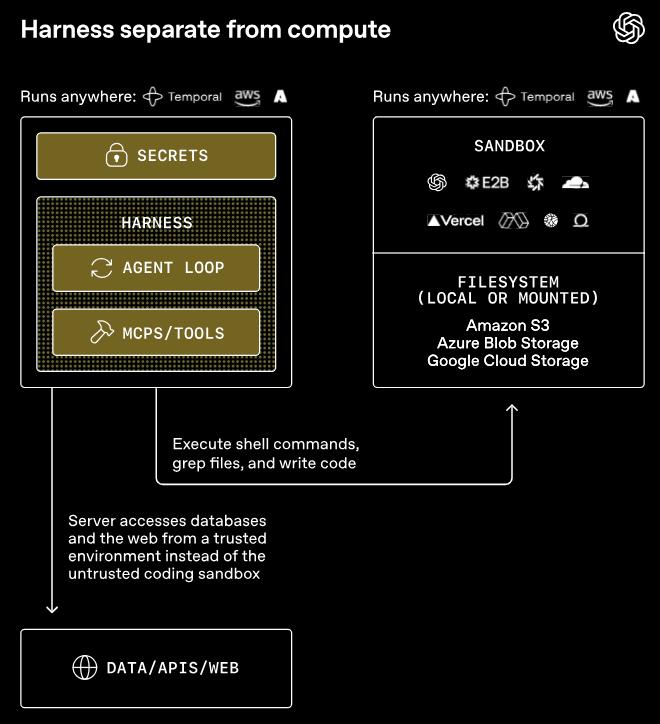
As a result, the sandbox contains neither API keys nor sensitive credentials. The sandbox itself is entirely isolated and can even be disconnected from the network, with no external traffic.
This is not just a minor security improvement; it represents a paradigm shift in the entire agent architecture.

900-Page Insurance Claim 100% Extracted by Agent
The separation of harness and compute has led to a sudden expansion of the sandbox vendor ecosystem. In this release, seven sandbox vendors—Blaxel, Cloudflare, Daytona, E2B, Modal, Runloop, and Vercel—were officially supported.

The key to the simultaneous integration of these seven vendors lies in OpenAI’s introduction of an abstraction layer called Manifest—a configuration list describing the agent’s workspace.
This Manifest details which local files to mount, where to pull data from cloud storage, and where to write outputs, covering AWS S3, Google Cloud Storage, Azure Blob Storage, and Cloudflare R2.
Crucially, this Manifest is decoupled from specific sandbox vendors. An agent written for E2B today can easily switch to Modal tomorrow without rewriting code—just a single line of configuration change. Teams can choose the cheapest or closest sandbox to their data.
An official minimal example demonstrates an agent running in a local sandbox, mounted with a financial report directory, comparing three financial metrics between FY2025 and FY2024, with core code under 20 lines.

Additionally, two new capabilities critical for long-running tasks are snapshot and state recovery, allowing the sandbox container to resume from checkpoints, and multi-sandbox parallelism + sub-agent isolation environments, solving scalability issues.
This gives agents their first native capabilities for “resuming after disconnection” and “operating in parallel.”
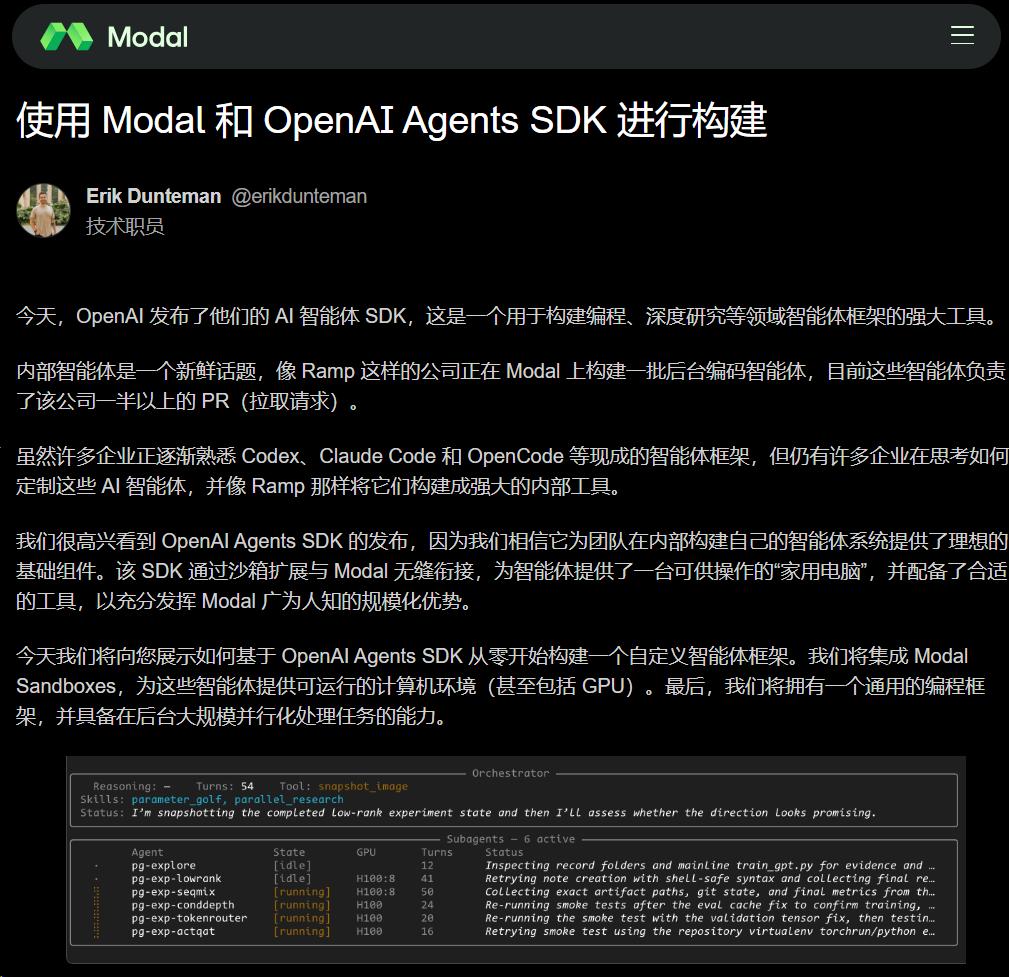
In a technical article, Erik Dunteman from the Modal tech team revealed a detail:
Ramp has used Modal to run a backend coding army of agents, with over half of the company’s PRs created by these agents.
Moreover, Stripe disclosed earlier this year that its internal AI agents produce over 1,000 PRs weekly.
Both companies experienced a significant productivity leap after acquiring mature agent infrastructure, which was previously only accessible to leading firms.
FurtherAI CTO Sashank Gondala shared that their agent successfully extracted information from a 900-page insurance claim document with a 100% success rate.
The combination of 900 pages, 100%, and insurance claims signifies a high level of difficulty, as industry veterans know that failing at any page was common in the past.

Douglas Adams, a developer at Tomoro AI, provided another set of hard numbers, stating that agents with similar capabilities now require six times less code than before.

Carter Rabasa, head of developer relations at Box, submitted business data along with bash/python as tools, allowing the agent to run a complete invoice reconciliation process in the sandbox. Surprisingly, the first trial was successful.
The sandbox is perfect for running agent-generated code.

OpenAI Takes on Infrastructure, Leaving LangChain and Others Nowhere to Hide
At this level, the true impact of this release on the industry becomes evident.
How have third-party agent frameworks like LangChain, LangGraph, CrewAI, and AutoGen survived over the past year? The answer lies in filling the gaps left by OpenAI’s native SDK, which was not sufficiently “production-ready”.
Orchestration, memory management, guardrails, tracking, and multi-agent collaboration were the main battlegrounds for these third-party frameworks.
Now, OpenAI has taken over all these battlegrounds in one fell swoop. They are establishing the infrastructure layer for the agent world, and third-party frameworks must either move to higher levels (orchestration, vertical scenarios) or lower levels (dedicated sandboxes, specialized tools). The middle ground has been solidified by OpenAI.
Furthermore, OpenAI’s claim of “compatibility with all sandbox service providers” effectively incorporates these vendors into OpenAI’s ecosystem. What may still be partners today could become mere “component suppliers” within OpenAI’s ecosystem tomorrow.
Python First, TypeScript in the Queue
Although everything is not perfect yet, with new harness and sandbox capabilities currently available only in Python while the TypeScript version is planned for future updates, the direction is clear.
With GPT-5.4 featuring native computer use, the Agents SDK has provided a true runtime environment. The next step is for more developers to build business logic on this infrastructure.
From now on, startups creating agent frameworks will reassess their positioning, sandbox vendors will consider whether they can handle OpenAI’s traffic, and teams developing agent applications will weigh the need to migrate.
What some called a “routine upgrade with no surprises” when GPT-5.4 was released is now being recognized as the true surprise just 40 days later.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.